Tutorial 9: Two-sample t-tests
Statistical errors, significance level (alpha), statistical power, F-test for variance ratios, and paired and two-sample t-test
Week of November 4, 2024
(9th week of classes)
How the tutorials work
The DEADLINE for your report is always at the end of the tutorial.
The INSTRUCTIONS for this report is found at the end of the tutorial.
While students may eventually be able to complete their reports independently, we strongly recommend attending the synchronous lab/tutorial sessions. Please note that your TA is not responsible for providing assistance with lab reports outside of these scheduled sessions.
The REPORT INSTRUCTIONS (what you need to do to get the marks for this report) is found at the end of this tutorial.
Your TAs
Section 0101 (Tuesday): 13:15-16:00 - Aliénor Stahl (a.stahl67@gmail.com)
Section 0103 (Thursday): 13:15-16:00 - Alexandra Engler (alexandra.engler@hotmail.fr)
Understanding significance level (alpha), Type I error and Type II error.
The key takeaway from this initial part of the tutorial is:When making inferences from samples, we face a trade-off: to control the risk of making one type of error (Type I or false positives), we must accept a manageable risk of making another (Type II or false negatives).
To grasp the concept of the significance level (alpha level)—the probability of committing a Type I error in a test—we’ll use the one-sample t-test (introduced in the last tutorial) to test the null hypothesis that human body temperature is 98.6°F (or 37°C, as commonly taught). Keep in mind that the principles we discuss here apply broadly to any statistical test!
Let’s assume the true population mean (which, in reality, we never know) is indeed \(\mu = 98.6^\circ\)F, and that the distribution of body temperatures in this population is normally distributed with a true standard deviation (sigma) of 2°F. Now, we’ll draw a sample from this population (25 individuals—the same sample size as in the body temperature study discussed in our lectures) and test whether we should reject the null hypothesis that the mean body temperature is 98.6°F.
This setup may seem redundant or obvious, as we’re sampling from a population with a known mean of 98.6°F to test the null hypothesis that the population mean is indeed 98.6°F. However, this “obviousness” (yes, that’s a real word!) can actually help clarify the principles underlying statistical tests.
Let’s start by taking a single sample from the statistical population:
sample.Temperature <- rnorm(n=25,mean=98.6,sd=2)
sample.Temperature
mean(sample.Temperature)Although the sample is drawn from a population with a mean temperature of 98.6°F, the sample mean is unlikely to match this population value exactly—this difference is due to sampling error (not sampling bias, as the values were randomly selected; rnorm ensures random sampling) and is simply a result of chance. This should be second nature by now!
Next, we’ll test whether we should reject the null hypothesis based on our sample mean. Let’s quickly recap the null and alternative hypotheses for this scenario:
H0 (null hypothesis): the mean human body temperature is 98.6°F.
HA (alternative hypothesis): the mean human body temperature is different from 98.6°F.
Let’s conduct the one-sample t-test on your sample above:
t.test (sample.Temperature, mu=98.6)To extract just the p-value, simply:
t.test(sample.Temperature, mu=98.6)$p.valueMost likely, the p-value (assuming an alpha level of 0.05) was not significant (i.e., p-value > 0.05). But if it was, don’t be surprised. Here’s why this can happen: you may have committed a Type I error, where the test result was significant even though the null hypothesis was true. While making Type I errors (false positives, i.e., rejecting when you shouldn’t) isn’t ideal, they occur at the rate set by alpha (the significance level).
Accepting a low risk (e.g., 0.05 or 0.01) of Type I errors is what enables us to make inferences within the framework of statistical hypothesis testing.
A non-significant test result should come as no surprise, as the sample was drawn from a population with a true mean temperature of 98.6°F. Recall that in statistical hypothesis testing, we begin by assuming the null hypothesis is true (i.e., population mean = \(\mu\) = 98.6°F) and use the appropriate sampling distribution to account for sampling variation in the statistic of interest. In this case, the appropriate sampling distribution for sample means is the t-distribution.
Let’s review first what type I and type II errors are:

This memory aid (unrelated to samples) may help you better associate Type I and Type II errors with false positives and false negatives, respectively:

Now, let’s draw a large number of samples from the population we specified earlier (population mean = 98.6°F) and test each sample against the null hypothesis:
number.samples <- 100000
samples.TempEqual.H0 <- replicate(number.samples,rnorm(n=25,mean=98.6,sd=2))
dim(samples.TempEqual.H0)And for each sample, let’s run a t-test and extract its associated p-value; MARGIN is set below to 2 because we want to run the t-test in each column of the matrix where each sample was saved samples.Temp generated just above:
p.values <- apply(samples.TempEqual.H0,MARGIN=2,FUN=function(x) t.test(x, mu=98.6)$p.value)
length(p.values)
head(p.values)The vector p.values holds all 100,000 p-values from t-tests conducted on each sample of 25 individuals, each drawn from a population with the same mean as the theoretical population assumed under the null hypothesis. Now, let’s calculate the percentage of tests (based on these samples) that produced significant p-values. What do you think this percentage will be?
alpha <- 0.05
n.rejections<-length(which(p.values<=alpha))/number.samples
n.rejections
n.rejections * 100 # percentageAs expected, the number of rejections closely aligns with the alpha level, \(\alpha = 0.05\) (in this case, it was 0.04996), meaning about 5% of tests on these samples were statistically significant. If we had set alpha to 0.01, then only about 1% of the samples would have been rejected. The slight deviation from exactly 0.05 is due to taking 100,000 samples rather than an infinite number from the statistical population of interest.
So, what does the significance level (\(\alpha\)) represent? It corresponds to the proportion of values considered significant when the null hypothesis is true. This is true here because we tested sample values from a population with the same mean as the theoretical population, meaning alpha is the probability of committing a Type I error. Thus, since the samples came from the same theoretical population assumed under the null hypothesis, the number of rejections aligns with alpha.
Now, consider what would happen if we set alpha to zero:
alpha <- 0.00
n.rejections<-length(which(p.values<=alpha))/number.samples
n.rejectionsWith alpha set to zero, we obviously don’t reject anything, as no p-value can be less than zero. This means we avoid committing any Type I errors. However, we would also never reject a null hypothesis, even in cases where it’s actually false, as we’ll discuss next.
This is the essence of the statistical hypothesis testing framework! We begin by identifying the appropriate sampling distribution under the assumption that the null hypothesis is true—here, the t-distribution. We then designate an alpha percentage of the t-values as significant, fully aware that these represent potential Type I errors. Why do we do this? Because we want to determine how unlikely it is to observe a sample mean (or a more extreme one) given the null hypothesis—in this case, using the t-distribution.
If we set \(\alpha = 0\), rejecting any null hypothesis becomes impossible. Let’s see this in action by taking a sample from a population with a higher mean temperature, say 99.8°F, while still testing against the original null hypothesis.
number.samples <- 100000
samples.TempDiferent.H0 <- replicate(number.samples,rnorm(n=25,mean=99.8,sd=2))
p.values <- apply(samples.TempDiferent.H0 ,MARGIN=2,FUN=function(x) t.test(x, mu=98.6)$p.value)
alpha <- 0.05
n.rejections<-length(which(p.values<=alpha))/number.samples
n.rejectionsThe number of rejections is around 0.82, meaning 82% of the samples were significant. This value represents the test’s statistical power (as discussed in our lectures). Statistical power is the probability of rejecting the null hypothesis when it is actually false. Here, we know the null hypothesis is false because the samples came from a population with a different mean than that assumed under the null hypothesis.
However, since we didn’t reject the null hypothesis in 100% of tests, we did commit some Type II errors. Specifically, 18% of the samples led to a non-rejection of the null hypothesis (1 - 0.82). As we covered in lecture, Type II error = 1 - statistical power.
But what happens with set an \(\alpha\) equal to zero:
alpha <- 0.00
n.rejections<-length(which(p.values<=alpha))/number.samples
n.rejectionsOnce again, we don’t reject any of the 100,000 tests, as no p-value can be less than zero. This means we’ve committed 100,000 Type II errors. To avoid this, we must accept some risk of rejecting the null hypothesis when it’s actually true—this is the risk of committing a Type I error, set by alpha. By doing so, we can reject the null hypothesis in cases where it’s false, thus reducing the number of Type II errors.
Remember, statistics are based on samples, and we never know the true value of a population parameter. Accepting a small chance of Type I errors (at a risk equal to alpha) allows us to avoid the greater risk of Type II errors. Recall the key point mentioned at the beginning of this tutorial?
When making inferences from samples, we face a trade-off: to control the risk of making one type of error (Type I or false positives), we must accept a manageable risk of making another (Type II or false negatives).
We hope that this now makes sense to you!
Paired comparison between two-sample means.
Are males with high testosterone incurring costs for their increased mating success in other areas?
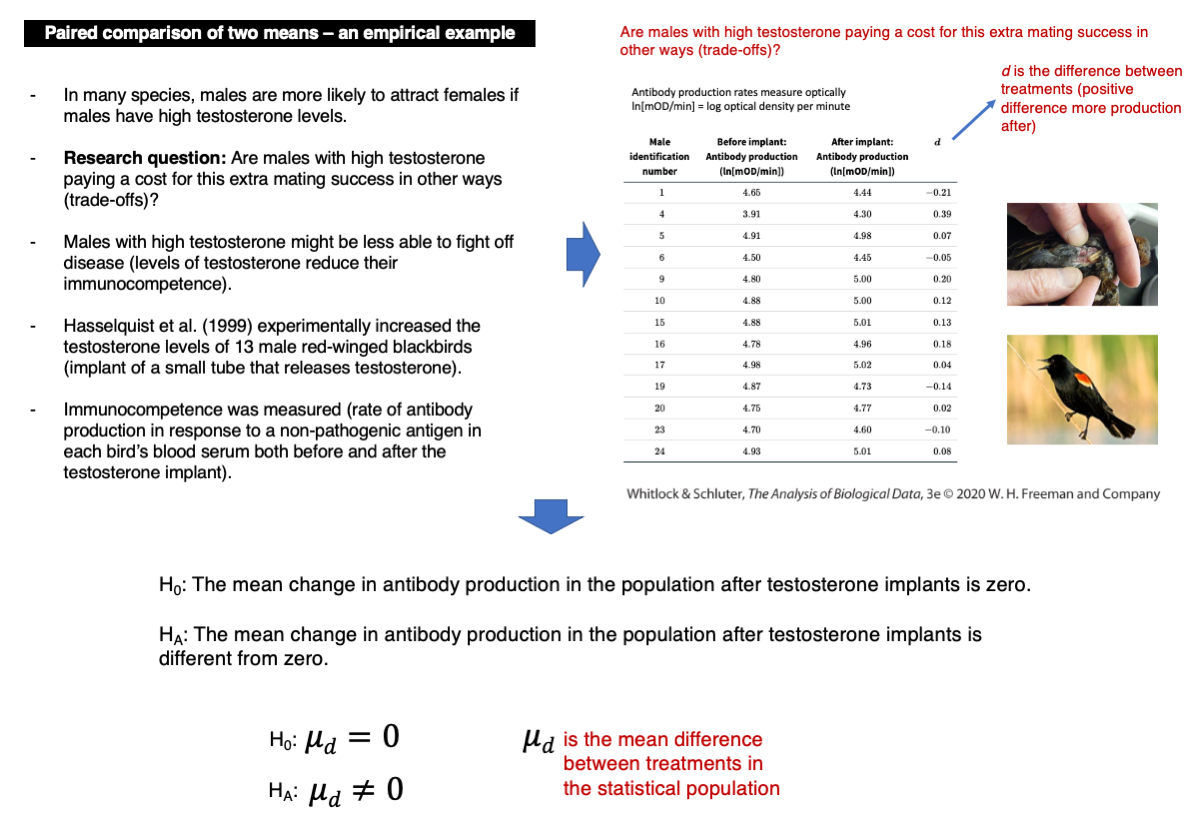
We will analyze data on individual differences in immunocompetence before and after increasing testosterone levels in red-winged blackbirds. Immunocompetence is measured as the logarithm of optical density, indicating antibody production per minute (ln[mOD/min]).
Download the testosterone data file
Now upload and inspect the data:
blackbird <- read.csv("chap12e2BlackbirdTestosterone.csv")
View(blackbird)The original data differs significantly from what we would expect normally distributed data to look like (we’ll explore formal methods for assessing normality later in the course).
differences.d <- blackbird$afterImplant - blackbird$beforeImplant
hist(differences.d, col = "firebrick")The data were log-transformed to make the data closer to normality. Calculate differences between after and before now:
differences.d <- blackbird$logAfterImplant - blackbird$logBeforeImplant
hist(differences.d, col = "firebrick")Conduct the t-test:
t.test(differences.d)Given the p-value and assuming an alpha = 0.05, we should not reject the null hypothesis (p-value = 0.2277).
Testing for the difference between two independent sample means when the two samples can be assumed to have equal variances
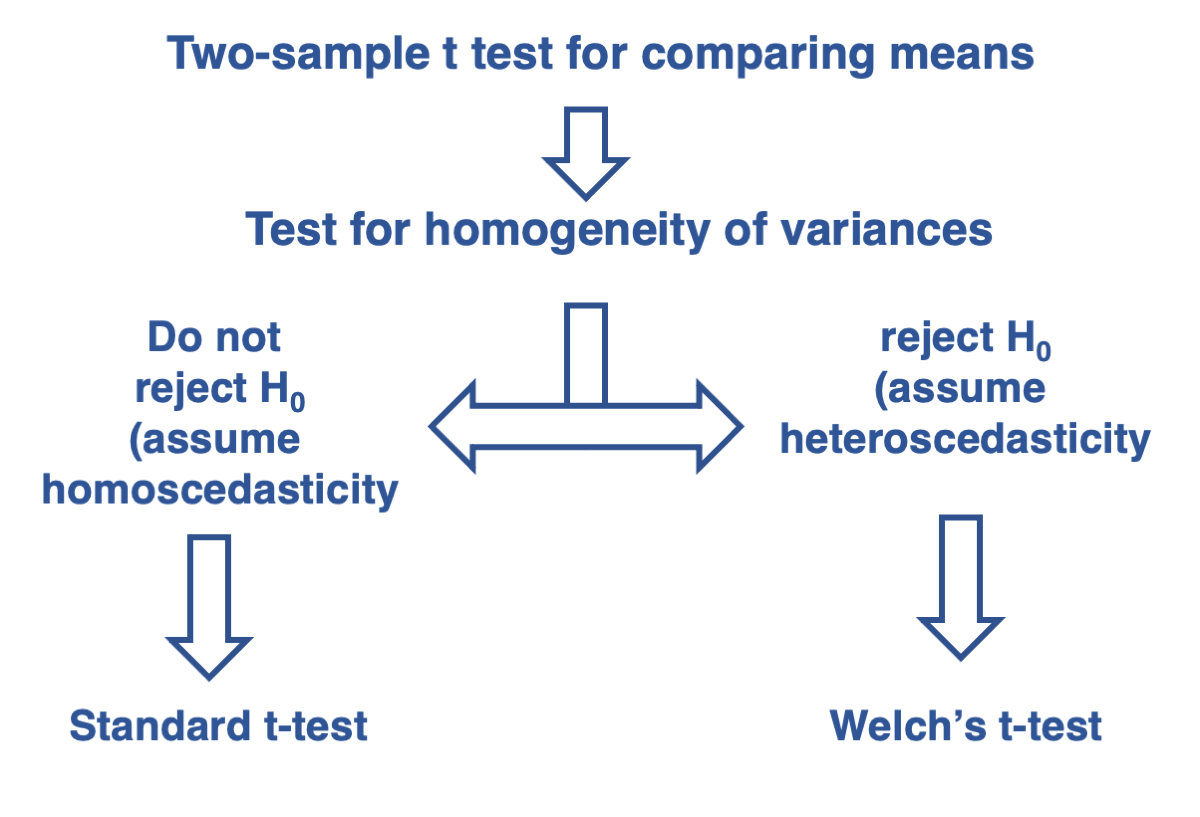
As we covered in Lecture 15, the t-test for two independent samples assumes that the populations from which the samples are drawn have equal variances. This assumption is essential for choosing the appropriate type of t-test. Remember our decision tree from the end of Lecture 15:
Do spikes help protect horned lizards from predation (being eaten)?
This is the problem we covered in Lecture 14 as an empirical example where the two-sample t-test was covered:

Download the horned lizard data file
Now upload and inspect the data:
lizard <- read.csv("chap12e3HornedLizards.csv")
View(lizard)Let’s start by calculating the variances of each group of individuals, i.e., living and killed individuals:
living <- subset(lizard,Survival=="living")
length(living)
var(living$squamosalHornLength)
killed <- subset(lizard,Survival=="killed")
length(living)
var(killed$squamosalHornLength)The variances for the living and killed individuals are 6.92 mm2 and 7.34 mm2, respectively. Although these values are close, we still need to test for homogeneity of variances.
var.test(squamosalHornLength ~ Survival, lizard, alternative = "two.sided")The null hypothesis should not be rejected (p-value = 0.7859).
Therefore, we can use the standard t-test for comparing two independent samples with the t.test function. Pay attention to the argument var.equal, which specifies that the t-test assumes equal variances between the two populations. This assumption was tested above, and the p-value indicates that it is reasonable to make this assumption.
t.test(squamosalHornLength ~ Survival, data = lizard, var.equal = TRUE)The p-value is 0.0000227 and we should reject the null hypothesis. The statistical conclusion is that lizards killed by shrikes and living lizard differ significantly in mean horn length.
Let’s calculate the mean of each sample:
mean(living$squamosalHornLength)
mean(killed$squamosalHornLength)Because the sample mean of horn size of the living lizards is greater (24.28 mm) than the killed lizards (21.99 mm), we conclude that we have evidence that horn size is a protection against predation.
Testing for the difference between two independent sample means when the two samples CANNOT be assumed to have equal variances
Does the presence of brook trout affect the survivorship of salmon?
This is the problem we covered in lecture 15 as an empirical example where the two-sample Welch’s t-test was covered:

Now upload and inspect the data:
chinook <- read.csv("chap12e4ChinookWithBrookTrout.csv")
View(chinook)
names(chinook)Let’s start by calculating the variances of each group of streams, i.e., with and without brook trout :
BrookPresent <- subset(chinook,troutTreatment=="present")
var(BrookPresent$proportionSurvived)
BrookAbsent <- subset(chinook,troutTreatment=="absent")
var(BrookAbsent$proportionSurvived)The variance of proportion of chinook salmon individuals that survived in streams with brook trout is 0.00088 and without brook trout is 0.01074. If The variance ratio is indeed quite high:
var(BrookAbsent$proportionSurvived)/var(BrookPresent$proportionSurvived)The variance when brook trout was absent is 12.17 times greater than when brook trout was present.
This is a strong indication that one variance is much higher than the other, but are the two variances statistically different? The hypotheses are:
H0: The population variances of the proportion of chinook salmon surviving do not differ with and without brook trout. HA: The population variances of the proportion of chinook salmon surviving differ with and without brook trout.
var.test(proportionSurvived ~ troutTreatment , data = chinook)The p-value is 0.01589 and based on an alpha of 0.05, we reject the null hypothesis and we cannot assume that their variance are equal (homogenous or homoscedastic).
Since the null hypothesis of homogeneity of variances (homoscedasticity) is rejected, we should use the two-sample Welch’s t-test. This can be done by setting the argument var.equal to FALSE, which assumes that the two samples come from populations with different variances.
H0: The mean proportion of chinook surviving is the same in streams with and without brook trout.
HA: The mean proportion of chinook surviving differs in streams with and without brook trout.
t.test(proportionSurvived ~ troutTreatment , data = chinook,var.equal = FALSE)Report instructions
By now, you’re likely accustomed to solving many tutorial report problems by copying and pasting code from the tutorial and making the necessary adjustments to address the specific problem at hand. This approach provides valuable practice and reinforces your understanding of the concepts covered.
Part 1: Based on a significance level (alpha) of 0.05, what is the statistical conclusion for the test you just performed (i.e., the t-test for the chinook salmon problem)? What is the scientific conclusion? (no code required)
Part 2: Using the simulations from the first part of the tutorial, write code to estimate the statistical power (with alpha = 0.05) of the test based on a population mean of 99.7°F for the following sample sizes: n = 30, 60, and 110 observations. Did statistical power increase or decrease with sample size? (code required)
Part 3: Repeat the exact same simulation as in Part 2, but this time set \(\alpha\) = 0.01. Simply copy and paste the code you created, but change alpha to 0.01. Was the power smaller or greater than for alpha = 0.05 with the same sample sizes? (code required)
Submit the report in an RStudio file through Moodle.